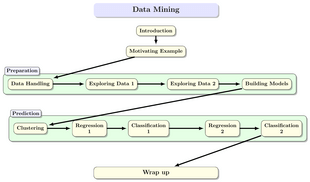
Welcome to Data Mining,
We will start this module with a warm up lab to set up software and some basic data analysis. The formal lecture will give an overview of the module — what will be covered, how it will be delivered and assessed.
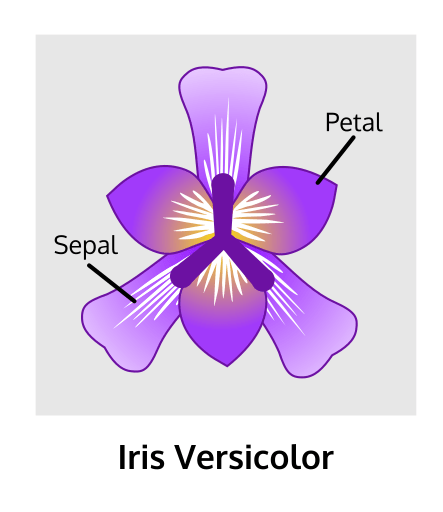
This week we review some of the most useful pandas commands and look at how to classify iris plants by species

Introduction to Python and Numpy
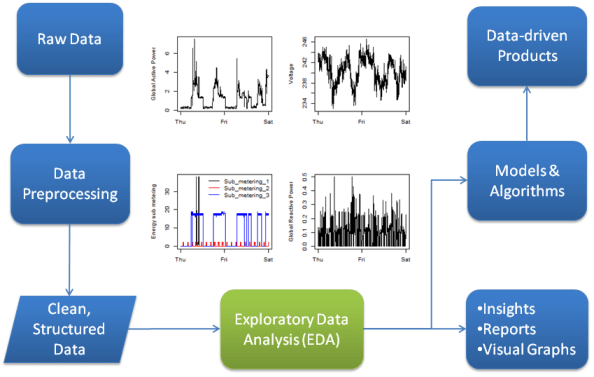
Before we begin to think about constructing models representing our data we need to see what kind of data we have, what is being measured, how clean it is, etc.
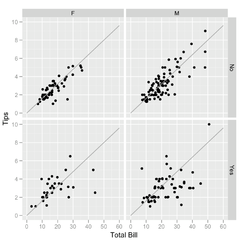
Continuing our review of Exploratory Data analysis, we consider richer analytics on data, leading to identification of features for prediction
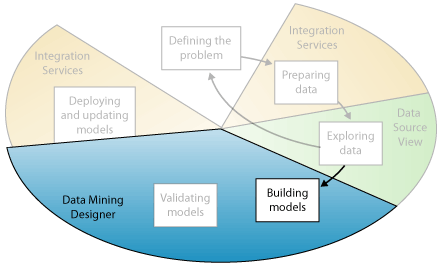
This week we will discuss general concepts/issues in the construction of data mining models.
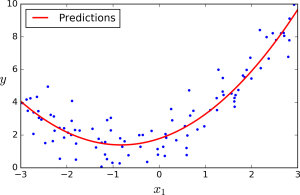
Sometimes we need to predict a numeric value or set of such values, given existing (training) data
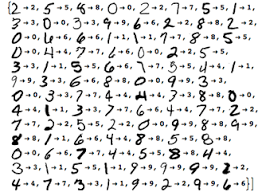
Given labeled training data, develop models to classify new data based on what we have seen in the training data
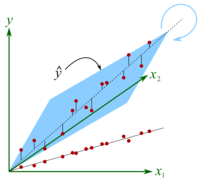
We continue our introduction to regression, considering how to make it more robust.
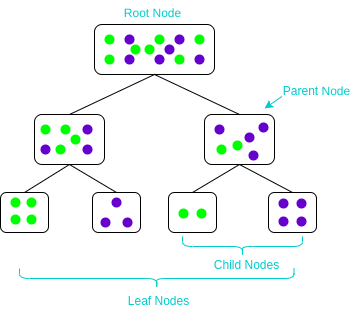
Classification using techniques that use probability-based models
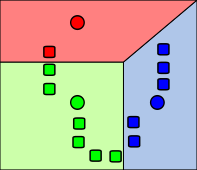
Given unlabeled data, look for subsets that help to improve understanding of the overall data set